By Sanjeev Datta, Consultant for PerformanceG2
There are multiple ways of enhancing the performance of TM1 using tools and techniques. This week for my 3-part blog series, I will be discussing Spreadsheet Techniques.
Spreadsheet Techniques
Following are techniques used on spreadsheets to enhance performance on TM1 servers:
DBR: This is a worksheet function valid only in worksheets. It retrieves a value from a specified TM1 cube and can be used to write values to the database when all the arguments are element values.
Syntax: DBR(cube, e1, e2,[…en])
DBRW: This is a worksheet function valid only in worksheets. This function is similar to the DBR function but is used to reduce network traffic and hence is extremely useful on Wide Area Networks. When implemented, DBRW function forces TM1 to use “bundles” rather than individual read/writes from/to the database.
Syntax: DBRW(cube, e1, e2,[…en])
ELCOMP: This is a worksheet function valid only in worksheets. It returns the name of a child of a consolidated element in a specified dimension. It is similar to the DBR function in that it retrieves a value from a specified TM1 cube but it also results in a round trip between the server and Excel.
Syntax: ELCOMP(dimension, element, index)
Dimension Ordering and Cube Optimizer: Dimension ordering can have significant impact on memory consumption as well as recalculation times in a TM1 server environment and its best to sort dimensions in 2 categories: Sparse & Dense Dimensions before creating cubes.
A sparse dimension would be Products & Regions, for example, where not every products is sold in every region. On the other hand, a Dense Dimension would be a month/time where you will always have a Budget amount in every month of the year.
As a general recommendation, the ordering of dimensions should be: smallest sparse to largest sparse followed by smallest dense to largest dense.
In practice, design the cubes with dimensions in “natural business” order and then use the Dimension Optimizer as necessary. Re-ordering does not break the “DB” references.
As a best practice, use the time and measures dimension at the end always.
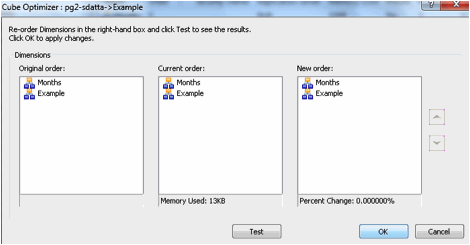
Cube Optimizer: The Cube Optimizer feature in TM1 Server Explorer lets you optimize the created cubes to consume less memory and improve performance. Over time as Business needs and Dimensional priority change, cube optimization is useful especially as re-calculation in TM1 is RAM-based i.e. “on-the-fly”.
The internal re-ordering of cube dimensions in TM1 is valuable for tuning sparse cubes, large dimensions or simply large cubes. As a note, dimensional ordering and cube optimization require twice the amount of the cube size. For example, if a cube size is 50MB, 100MB must be available in memory to perform cube optimization.
Other TM1 Techniques
Calculations are defined implicitly by dimension hierarchies and are an order of magnitude faster than Rules and should be used whenever possible.
Rules on the other hand, allow defining any cell as an arbitrary calculation of any other cells in any cube.
For best practice, place calculations you expect to change often in rules, even though the “math” could be done faster with consolidations.
Reduce over-feeding by using Conditional Feeders when using TM1 Rules.
